The Eval That Decides Whether You Ship
The companion to this post described the lightweight evaluation: the one you run under a clock, when a campaign is active and a response ships in hours. This post describes the other instrument. The heavy evaluation is what gates a model release. It is slow, deliberate, and expensive, and those properties are features rather than defects.
I am going to walk through it using a hypothetical but realistic surface: lookalike-domain impersonation detection on an enterprise collaboration platform. The platform allows external messaging across organizational boundaries. The threat is a sender outside the company impersonating a trusted identity by registering a domain that closely resembles a trusted partner. The product response is a warning banner shown to the recipient. None of the specifics below are tied to any particular vendor; the framework is what transfers, not the numbers.
Card A: The Baseline (Generic)
To: employee@yourcompany.com
Hi Team, here is the invoice for this month...
Card B: The Intervention
To: employee@yourcompany.com
Hi Team, here is the invoice for this month...
A note on the numbers, in fact. The threshold values in this post are illustrative. In a real deployment, specific thresholds, dataset construction details, and operational alert values stay internal, because in an adversarial domain the evaluation itself is a training signal for the next attack. What is safe to publish is the framework and the reasoning. What is not safe to publish is the operational detail. Holding that line is itself part of the discipline.
The structure
The heavy evaluation has ten sections. They fall into three groups: what you are claiming and against what (sections one through three), how you define and measure success (sections four through six), and how you keep the evaluation honest over time and under adversarial pressure (sections seven through ten).
What you are claiming
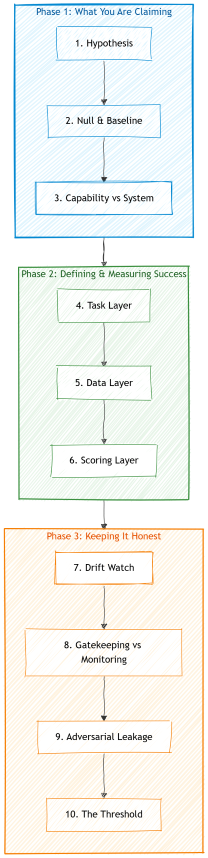
Section 1: Hypothesis
Every evaluation is a hypothesis test. The hypothesis names a system, a task, a success metric, and a baseline, in a single sentence. If any of the four is missing, you do not have a hypothesis; you have a number that will feel like one.
The most useful question to ask before building any evaluation is: what would convince me I am wrong. If you cannot answer that before the data arrives, you are not measuring anything. You are preparing to confirm what you already believe.
For the banner system, the hypothesis is a product claim, not a model claim. The model could classify perfectly and the product could still fail, because the product depends on the banner changing what the recipient does. So the hypothesis is about behavior: the lookalike-specific banner reduces recipient engagement with flagged impersonation messages relative to the generic external-sender banner the platform already shows, by some committed effect size, measured over a defined window on a defined population.
The baseline matters enormously here. The comparison is not against no banner; it is against the generic banner that already ships. Comparing against nothing would inflate the apparent effect by taking credit for value the generic banner already delivers. This is one of the most common forms of evaluation malpractice in mature products: shipping a fancier version of an existing feature and claiming credit for the value the simpler version already produced.
Section 2: Null and baseline
The baseline is what you compare against, and it determines whether every number in the evaluation means anything.
The discipline most teams skip is naming the baselines you considered and rejected. For the banner, the candidates were: no banner at all, rejected because it inflates the effect and ignores the generic banner that already ships; blocking the message instead of warning, rejected because the false-positive cost of blocking a legitimate new partner is too high; and a per-tenant admin-configured banner, rejected because administrators in practice accept defaults rather than configure custom rules, so the realistic counterfactual is no per-tenant banner at all.
The null is the definition of no effect, written quantitatively. You commit to a floor below which the result counts as failure, and you commit to a statistical significance bar so that you can distinguish a real effect from sample noise. Both are committed before the data arrives. A passing result requires both a meaningful effect size and statistical significance; either one without the other is not a result you ship on.
Section 3: Capability eval or system eval
This distinction is the one product managers miss most often.
A capability evaluation tests the model in isolation: can it classify correctly on a curated dataset. A system evaluation tests the deployed pipeline: does the product produce the right outcome on real traffic. They are different questions with different owners, different inputs, and different consequences when they are wrong.
For the banner, both exist, and they are sequenced. The capability evaluation runs first, offline, on a labeled dataset, with no users exposed. If the model fails the capability bar, the system evaluation does not run at all, because exposing users to a model that fails basic classification is not worth the risk. Only after the capability bar is met does the system evaluation, an online test of banner effectiveness, begin.
The gating logic is asymmetric, and the asymmetry is deliberate. A capability failure blocks the system evaluation entirely. A capability success does not guarantee system success, because a perfectly accurate model can still fail to change recipient behavior. A system failure blocks shipping, regardless of how good the underlying model is. A system success is the shipping decision. A model that is highly precise but does not change behavior does not ship.
How you define and measure success
Section 4: Task layer
This is where most evaluations quietly fail, and it is the longest section for that reason.
The task layer defines what success looks like, precisely enough that two independent reviewers would assign the same label to the same example. The discipline is to write the label definition as an observable rule, not as an intent. Reviewers cannot read minds; a definition based on what the attacker is trying to do is unlabelable. The definition has to rest on observable properties: the sender domain, the recipient organization’s known contacts, the relationship history.
Three properties of a good task layer for this problem are worth drawing out.
First, the definition deliberately excludes content. In the current environment, machine-generated impersonation content reads indistinguishably from legitimate communication. The linguistic markers detectors leaned on for years are gone. A label definition should rest on signals that are expensive for an attacker to fake, such as domain identity and relationship history, rather than signals an attacker can mimic cheaply, such as content. This is a defining difference between an evaluation designed in the current era and one designed five years ago.
Second, the trust signal should be an affirmative recipient action rather than a passive observation. Counting messages exchanged is weak, because an attacker can manufacture volume. Counting accepted connection requests is strong, because acceptance is an explicit act of recognition by the recipient organization that is hard to fake without an actual relationship. This pattern, preferring affirmative actions over passive observations, recurs across identity, payments, and verification systems generally.
Third, the negative class is not the inverse of the positive class. This is the single most consequential error in the section. If the positive class is “similar domain, no prior trust,” the literal inverse includes every unrelated external sender, every internal message, every exactly-trusted partner. An evaluation built on that inverse will be dominated by trivially easy negatives, the model will classify them correctly by default, and the headline accuracy will look excellent while the model has learned nothing about the cases that actually matter. The useful negative class lives in the same population as the positive class and differs by a legitimacy signal: a sender that looks similar but is a verified subsidiary, a published partner, or an independently verifiable legitimate business. Those are the hard negatives, and an evaluation that does not concentrate on them is an evaluation that flatters the model.
The “Hard Negatives” Classification Grid
The Positive Class
Definition: Similar domain, no prior trust (The Attack) Examples: trvstedcorp.com, trusted-corp-support.com Dataset Volume: Constructed / Synthetic (Due to low base rate)
The Trivial Negatives
Definition: Unrelated external senders, internal traffic Examples: random-vendor.com, internal-hr@company.com Dataset Volume: Exclude or Minimize (Flats model accuracy)
The Hard Negatives
Definition: Similar domain, BUT verified legitimacy Examples: Subsidiary: trustedcorp.co.uk, Partner: trustedcorp-portal.com Dataset Volume: Maximum Volume (Where the model does real work)
The task layer also has to handle the structurally hardest case: a legitimate sender making first contact, who by definition has no relationship history and is therefore indistinguishable from an impersonator at the level of history alone. There is no clean answer here, only a tradeoff to be logged. One resolution treats organizational legitimacy as sufficient to suppress the warning, accepting that a well-resourced attacker who establishes plausible legitimacy will bypass the lookalike-specific banner. The justification, in the system I described, is that the generic external-sender banner still fires on these cases, so the bypass is not “no warning” but “the baseline warning without the additional layer.” Whether that justification holds depends on assumptions about the generic banner that should be written down and monitored, not assumed.
Section 5: Data layer
Where the data comes from, what distribution it represents, who labels it, and what biases they bring.
Several disciplines matter here. The class balance is constructed rather than natural, because impersonation is rare and a naturally sampled dataset would be so dominated by negatives that a model could score well by always guessing negative. Within the negatives, the hard sub-population gets the most volume, because that is where the model has to do real work. Sampling within each category is random rather than hand-picked, because hand-picking biases the evaluation toward the failures the team already imagines and misses the failures the model invents. Edge cases are deliberately over-sampled so that performance on them is statistically detectable.
The biases are named explicitly: pilot tenants skew security-conscious and may not represent the general population; security reviewers skew toward over-labeling because caution is professionally safer than a miss; historical confirmed cases over-represent attacks that bypassed prior detection. Each bias gets a stated mitigation. Naming the biases you cannot eliminate is more honest than pretending the dataset is clean.
There is a hard problem lurking here that deserves its own mention: the low base rate. In a domain where the genuine event rate is below one in tens of thousands, you will not collect enough natural positives in a pilot window to reach full statistical power. The realistic response is to supplement with synthetic examples and controlled red-team exercises, to report performance on natural and supplemented examples separately, and to accept wider confidence intervals than a high-volume product evaluation would tolerate. A team claiming abundant natural positives and tight confidence intervals in a rare-event domain is either operating at unusual scale or not being honest about its data.
Section 6: Scoring layer
Who or what assigns the score, and what biases the scorer brings.
For this system, capability scoring uses human binary labels from a small panel with majority vote, and system scoring uses behavioral outcomes from the online test. A machine judge was considered and rejected, because the task is a security classification where reviewer expertise matters and a machine judge has not been validated on this class of problem. The general principle holds regardless: a machine judge is itself a model, with its own biases and its own need for validation. “We used a model to judge” is the start of a measurement problem, not the end of one.
The scorer also needs its own drift watch. Reviewer agreement is recomputed periodically, and labeling pauses if agreement degrades, because reviewer drift and specification ambiguity emerge over time and silently corrupt the ground truth the whole evaluation rests on.
How you keep it honest
Section 7: Drift watch
In an adversarial domain, distribution drift is not a defect to be corrected; it is the entire point. The attacker is adapting to your detector continuously. Yesterday’s campaign is precisely the campaign that will not run tomorrow, because the attacker learned what was blocked.
This has a concrete consequence for evaluation: the held-out set has a half-life. As soon as it has been used a few times, it leaks into the development process, and in an adversarial domain it also goes stale because the real distribution moves. The response is a rotation policy, faster than the quarterly cadence that suffices for non-adversarial products, because the cost of a stale held-out set is higher when an adversary is optimizing against the gaps. The rotation cadence is a product and risk decision, not a tooling cadence, and treating it as merely an engineering schedule is a mistake.
The section also names specific scenarios that would make the evaluation stop meaning anything, with the triggers that would detect each and the action each would prompt. Naming the failure modes of your own evaluation in advance is what separates a living evaluation from a number that quietly decays.
Section 8: Gatekeeping versus monitoring
The same metric serves two purposes at two different bars.
Pre-deployment, the bar is high and conservative, because the goal is to avoid shipping a regression. Post-deployment, the bar is lower and more permissive within bounds, because production behavior naturally varies and treating monitoring like gating produces a stream of unnecessary rollbacks. Using the same threshold for both is a sign the team has not thought carefully about what each one is for.
Monitoring warnings trigger investigation; only action thresholds trigger action. Automatic rollback is generally avoided, because false alarms in monitoring are common and the cost of yanking a feature users have habituated to is real. The asymmetry between the two bars is the point: bias toward not shipping a regression before launch, bias toward not overreacting to noise after launch.
Section 9: Adversarial leakage
The evaluation is dual-use. Its existence tells an attacker how the system reasons: what the scope filter catches and therefore what falls outside it, where the known structural gaps are, what establishes trust and therefore what an attacker would want to manufacture.
This reshapes what is safe to share. The framework, the principles, and the structural reasoning are publishable. The specific threshold values, the dataset construction, the scorer composition, the monitoring alert values, and the exact features the model uses are not, because publishing them turns the evaluation into an attacker’s training set. Rotation serves a second purpose here: even a leaked or inferred dataset expires in operational value within a cycle.
The split between the public framework and the internal operational detail is a process discipline rather than a feature. It has to be maintained deliberately, in how documents are written and in how anything leaves the building. This post is itself an exercise of that discipline: the framework is here in full, and the operational numbers are illustrative rather than real.
Section 10: The threshold
The thresholds, committed before the data arrives.
The precision bar is set high, because the cost of a false positive is recipient mistrust of the banner, and banner fatigue is a one-way ratchet: once recipients learn to ignore the warning, it loses value for every future message. The recall bar is set lower than precision, because the cost of a miss is partially absorbed by the generic banner and other layers of the stack; the model is not the only line of defense, so recall does not need to be heroic. The effect-size floor on the behavioral metric is the line below which the additional engineering, monitoring, and adversarial-leakage cost of the lookalike-specific banner is not justified by its marginal value over the generic banner.
The discipline that holds all of this together is the commitment to write the thresholds before the data lands. After the data arrives, there is strong pressure to adjust the thresholds toward whatever the data shows. Pre-committing is the defense against that pressure. If the model misses the bar, the response is to improve the model, not to move the bar. Any adjustment after the fact has to be an explicit, documented decision with named reasoning, never a silent recalibration.
When to use which
The heavy evaluation runs once per major model change. It is the building code: slow, thorough, and designed to prevent the structural failures that a fast response cannot catch. The lightweight evaluation, described in the companion post, runs in hours and exists to respond to active campaigns without breaking legitimate traffic.
The two are linked by a single hand-off: every campaign the lightweight track responds to becomes data for the next heavy cycle. The fast track buys time. The slow track makes the response durable. A team with only the heavy track is too slow to respond to anything happening now. A team with only the lightweight track ships an ever-growing pile of unmaintained rules and eventually ships a regression it never measured.
The skill is not running either one well in isolation. The skill is knowing, every time something lands on your desk, which of the two the situation is asking for.
Archana Kumari writes about communications fraud, applied AI, and the systems that sit between them. More at archanakumari.fyi