The Eval You Run When the Clock Is Running
Most writing about evaluation assumes you have time. It assumes a held-out dataset, a labeling panel, a power analysis, weeks of iteration. That assumption is fine for shipping decisions. It is useless during an active attack.
In adversarial domains, a meaningful fraction of evaluation work happens under a clock. A campaign is running right now, your detector is missing it, and the right response ships in hours, not weeks. The heavy evaluation framework that protects you from shipping a regression is the wrong instrument for this moment. It is too slow, and slowness during an active campaign is itself a failure.
This post describes the lightweight evaluation: the framework you fill out when you are responding to a live threat. The companion post describes the heavy evaluation that gates model releases. The two are not the same tool used at different speeds. They are different tools for different problems, and knowing which one you are holding is one of the more important judgment calls in fraud product work.
What makes this different
The heavy evaluation answers the question: should we ship this model. The lightweight evaluation answers a narrower question: can we deploy this specific intervention against this specific campaign without breaking legitimate traffic, and can we do it today.
Three properties define the lightweight eval, and all three are consequences of the clock.
First, it is deliberately narrow. It does not validate the model. It does not measure recipient behavior change. It checks one thing: whether the intervention blasts through legitimate traffic. It is a tripwire, not an evaluation.
Second, the intervention it evaluates is time-bounded by default. It expires automatically after a committed window unless explicitly renewed. This is not a convenience; it is a control. The most common failure mode of fast-track fraud responses is that a temporary rule becomes permanent by accident, accumulating into a brittle, unmaintainable rule set that no one remembers the reason for. Automatic expiry prevents this.
Third, rollback is unilateral. The product manager gate exists for deploying the intervention, not for pulling it. Any on-call engineer can roll back based on pre-committed criteria without further discussion. Under a clock, the cost of a slow rollback is higher than the cost of an occasional unnecessary one.
The five sections
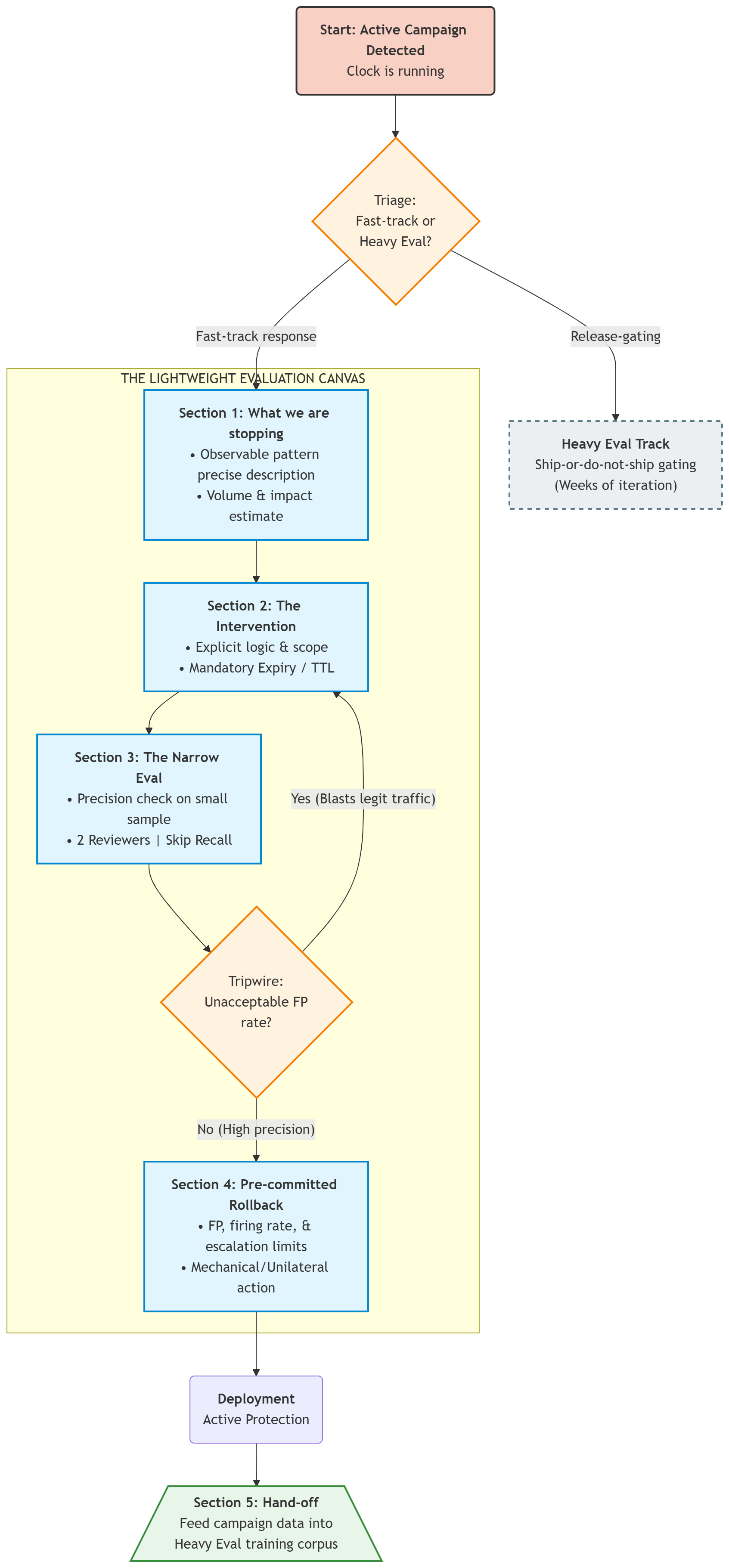
Section 1: What we are stopping, right now
One paragraph describing the active campaign. The specific pattern observed, the volume, and the impact estimate if one is available.
This is not a hypothesis. The campaign is real and confirmed. The question is not whether it exists; the question is what the fastest defensible response is. A useful description names the observable pattern precisely enough that an engineer could write a rule from it: the sender characteristics, the content characteristics, the targeting characteristics. Vague descriptions (“we are seeing a phishing wave”) produce vague interventions. Precise descriptions (“messages from domains registered in the past thirty days, visually similar to financial-services partner domains, containing payment-redirection language”) produce interventions you can actually deploy and measure.
Section 2: The intervention
What is being shipped. In most cases this is a rule, a blocklist addition, a threshold adjustment, or a temporary change to a warning surface. State the logic explicitly. State the scope: which population of traffic, which recipients, which sender patterns.
State the expiry. A lightweight intervention should carry an explicit time-to-live, typically measured in days. When the window closes, the intervention lifts unless someone makes an active decision to renew it. The expiry is part of the intervention specification, not an afterthought.
Section 3: The narrow eval
One precision check, on a small sample, before global deployment.
The sample is drawn from the campaign traffic the intervention will act on. Two reviewers label independently; under a clock, you do not convene the full panel a heavy eval would use. The bar is high precision, because during a campaign response the cost of a false positive is concentrated and visible: you are acting on a narrow slice of traffic, and over-blocking that slice produces immediate, attributable harm to legitimate senders.
Recall is not measured. This is the part that surprises people coming from heavy-eval habits. You are responding to a known campaign, not building a comprehensive detector. Whether the intervention catches impersonation attempts outside this campaign is irrelevant to this deployment. Measuring recall here would waste time you do not have on a question this intervention is not trying to answer.
The narrow eval has exactly one job: confirm the intervention does not harm legitimate traffic at an unacceptable rate. That is the whole tripwire.
Section 4: Rollback criteria, pre-committed
The conditions under which the intervention is pulled automatically, written down before it ships.
Typical criteria: a false-positive complaint rate above a committed hourly threshold; an intervention firing rate above some multiple of the pre-deployment estimate, which signals either an estimation error or scope drift; escalations from customer accounts above a defined tier. Each of these is a number you commit to before deployment, so that rollback is a mechanical decision rather than a negotiation in the middle of an incident.
Rollback is unilateral. This bears repeating because it inverts the usual approval flow. Deploying a fast intervention requires a product gate. Pulling one does not. The asymmetry is intentional: under a clock, you want deployment to be considered and rollback to be frictionless.
Section 5: Hand-off to the heavy track
When the campaign window closes, the campaign becomes data.
The traffic patterns, the intervention performance, and any confirmed positives feed the dataset for the next heavy evaluation cycle. The campaign you responded to becomes part of the corpus the next model version is trained and evaluated against.
This section is the connective tissue between the two tracks, and it is the section most teams skip. Without it, every campaign requires a fresh lightweight response forever, and the organization never converts incident response into durable capability. With it, attacker patterns accumulate into the model over time. The lightweight track buys time; the heavy track makes the response permanent; the hand-off is what links them.
The discipline that goes with it
The lightweight canvas comes with one habit: at the start of every incident, ask whether this is a fast-track response or a release-gating evaluation. If the answer is unclear, default to the fast track, because the cost of a slow response to an active campaign is higher than the cost of a fast response you refine later.
But defaulting to the fast track is not a license to skip the heavy track. The hand-off in Section 5 is what keeps the two honest. A team that only ever runs lightweight evals is shipping a growing pile of unmaintained rules. A team that only ever runs heavy evals is too slow to respond to anything happening now. You need both, and you need to know, every time, which one the situation calls for.
The companion post covers the heavy evaluation: the full ship-or-do-not-ship framework, and the reasoning behind every decision in it. If the lightweight eval is the response to a fire, the heavy eval is the building code.
Archana Kumari writes about communications fraud, applied AI, and the systems that sit between them. More at archanakumari.fyi